Works on: Windows 10 | Windows 8.1 | Windows 8 | Windows 7 | Windows 2012 SHA1 Hash: 511c513cdb56ed9ffd7a753c51adb23d1076772f Size: 925.03 KB File Format: zip
Rating: 2.173913043
out of 5
based on 23 user ratings
Publisher Website: External Link Downloads: 568 License: Demo / Trial Version
C# Web Scraping Library is a demo software by The Iron Web Scraper Development Team and works on Windows 10, Windows 8.1, Windows 8, Windows 7, Windows 2012.
You can download C# Web Scraping Library which is 925.03 KB in size and belongs to the software category Components Libraries. C# Web Scraping Library was released on 2017-03-15 and last updated on our database on 2017-04-16 and is currently at version 4.
Thank you for downloading from SoftPaz! Your download should start any moment now. It would be great if you could rate and share:
Rate this software:
Share in your network:
C# Web Scraping Library Description
The web-scraper for C# allows .Net developers to create logical that extract content from web applications and turn it into JSON, spreadsheets, C# objects or even SQL using simple C# and Linq code.
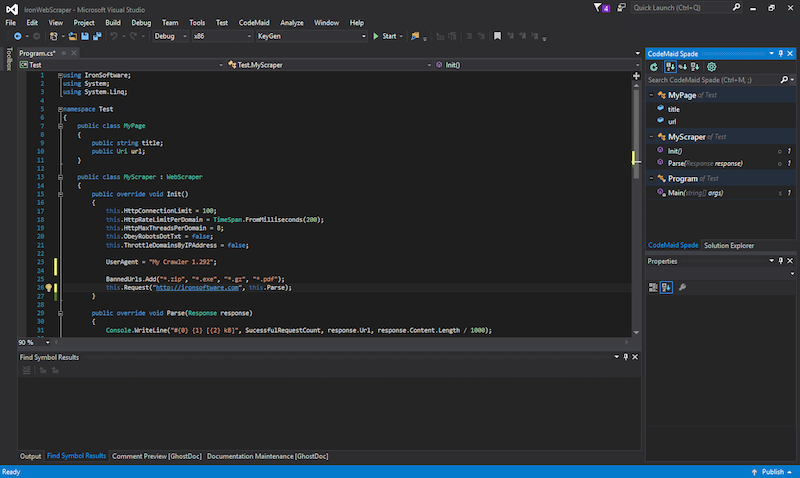
Iron WebScraper is a web scraping library for the .Net 4.5 and Core platform which allows developers to use clean, simple logic to reverse any web resource back into C# objects or SQL. It can extract pages using set-by-step (if-this-then-that) workflows, effortlessly scraping and parsing html, javascript, xml, RSS, pdfs and office documents on the internet or local intranets back into useful structured data.
This leaves the developer with clean, efficient web-scraping applications which are easy to understand and debug.
The C# Web Scraping Library is extremely polite, ensuring that no domain or IP address has too many concurrent requests. It intelligently throttles both client and server side looking for excessive CPU usage and slowing to an appropriate pace. In addition, it can obey robots.txt directives including bot specific crawl rates and limitation. The exact urls and content types to be strapped can be set using logical workflows and regex/wildcard rules.
Screen-scraping is made easier with identity control, automatically managing threads, rate limits, urls, duplicates, retries, proxies, headers and cookies into a an army of virtual browser which can mimic human behavior and even client buttons, fill in forms or log in behind security walls. This is useful for migrating legacy systems, populating enterprise search facilities and for statistical competitive analysis
Full documentation, support and downloadable DLLS for the C# Web Scraper are available from http://ironsoftware.com/csharp/webscraper/ , in addition to links to a .Net 4.5+ Nuget package with full Azure and Mono compatibility.





 Windows 7 and above
Windows 7 and above View Screenshots(1)
View Screenshots(1) Comments
Comments Download
Download






 Similar Software
Similar Software Recently Searched
Recently Searched Software Categories
Software Categories Trending Software
Trending Software


 Like Us
Like Us









